컴퓨터 비전의 모든 것
- Neural network 데이터에 포함된 정보를 압추갛여 weight를 주입하는 모델
핵심 3가지
- Data augmentation (데이터 논증)
- bias(편항된) 데이터를 사용하지 않게 할려고 만든 방법
- 학습된 데이터를 밝기 바꾸고 회전하고 자르서 사용
- OpenCV numpy 에서 사용할수 있다.
- 여라가지 다앵한 조합해서 사용
- Leveraging pre-trained information(사전 학습된 지식)
- 데이터를 적게 쓰고도 학습하기 위해
- 2.1 transfer learning
- 데이터 셋에서 학습하여 배웠던 지식을 다른 데이터셋에서 활용하는 기술
방법 1
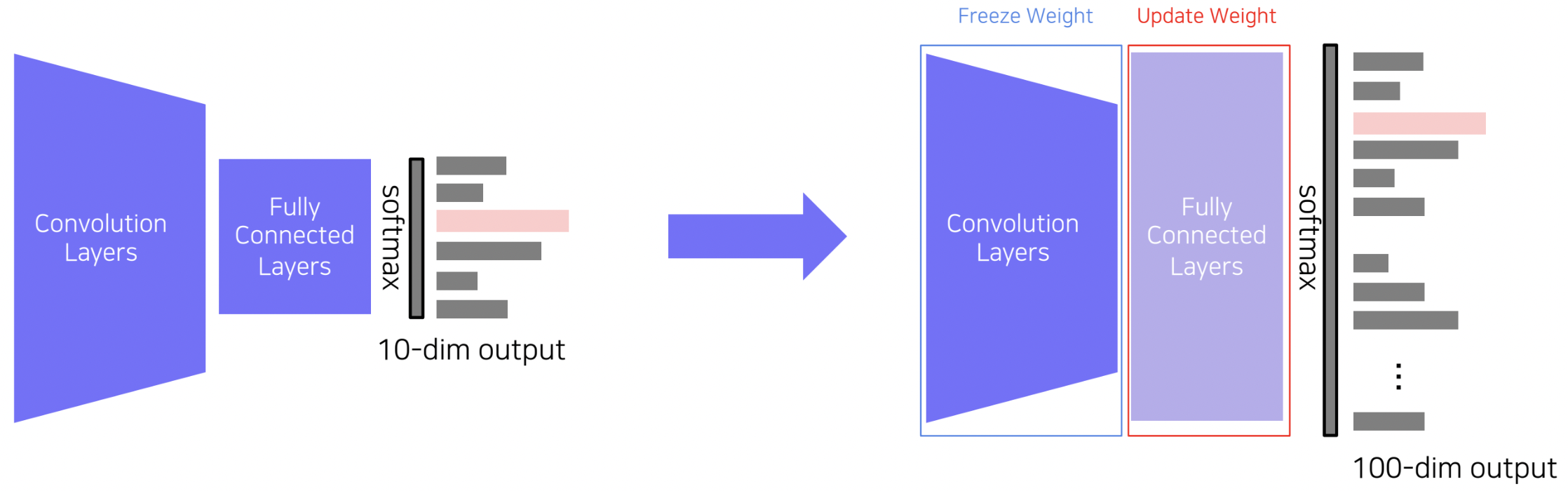 사전에 학습된 모델에서 마지막 Fc layer들만 뗴어내고, 새로운 FC layer들로 교체하여 기존 모델 가중치들은 학습시키지 않고(freeze), 새로 교체한 FC layer의 가중치만 업데이트하는 방식입니다. 적은 파라미터만 학습시키면 되기 때문에 작은 사이즈의 데이터셋으로도 비교적 좋은 성능을 기대할 수 있습니다.
사전에 학습된 모델에서 마지막 Fc layer들만 뗴어내고, 새로운 FC layer들로 교체하여 기존 모델 가중치들은 학습시키지 않고(freeze), 새로 교체한 FC layer의 가중치만 업데이트하는 방식입니다. 적은 파라미터만 학습시키면 되기 때문에 작은 사이즈의 데이터셋으로도 비교적 좋은 성능을 기대할 수 있습니다.
방법 2
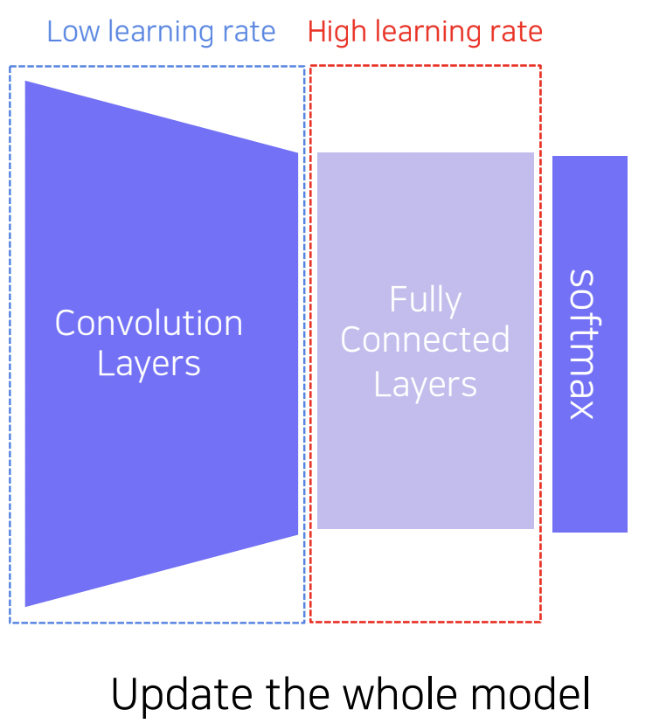 전체 모델을 그대로 fine-tuning 하는 방식입니다. 새로우 FC layer들로 교체하는 것은 동일하지만 Convolution layer의 가중치 또한 업데이트를 진행합니다. 다만 사전 학습된 지식을 최대한 보존하기 위해 Convolution layer의 learning rate는 FC layer에 비해 작은 값으로 설정하여 학습을 진행합니다. 첫번쨰 방식의 경우 데이터 사이즈가 정말 작은 경우 활용하기 좋은 방법이라고 볼수 있다.
전체 모델을 그대로 fine-tuning 하는 방식입니다. 새로우 FC layer들로 교체하는 것은 동일하지만 Convolution layer의 가중치 또한 업데이트를 진행합니다. 다만 사전 학습된 지식을 최대한 보존하기 위해 Convolution layer의 learning rate는 FC layer에 비해 작은 값으로 설정하여 학습을 진행합니다. 첫번쨰 방식의 경우 데이터 사이즈가 정말 작은 경우 활용하기 좋은 방법이라고 볼수 있다.
방법 3 Knowledge Distillation Teacher model을 활용하여 그보다 작은 Student model을 학습하는 방법입니다.
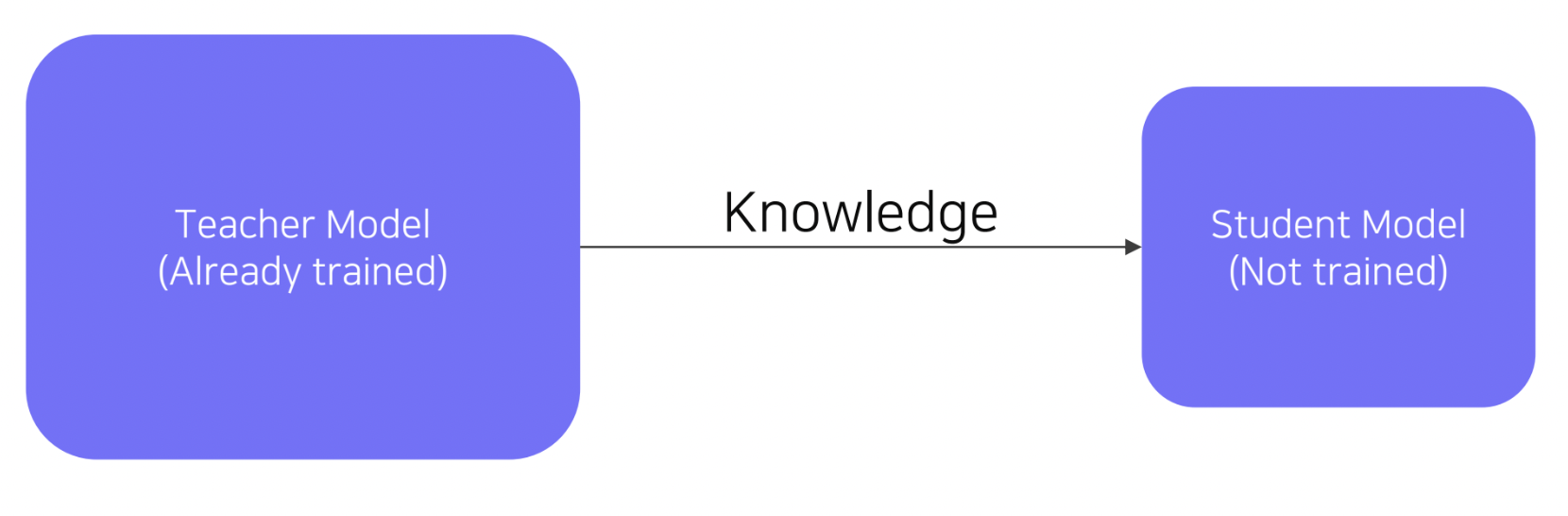
먼레이블 되지 않은 데이터세을 pseudo-labelling을 적용하기 위한 목적으로도 활용됩니다.
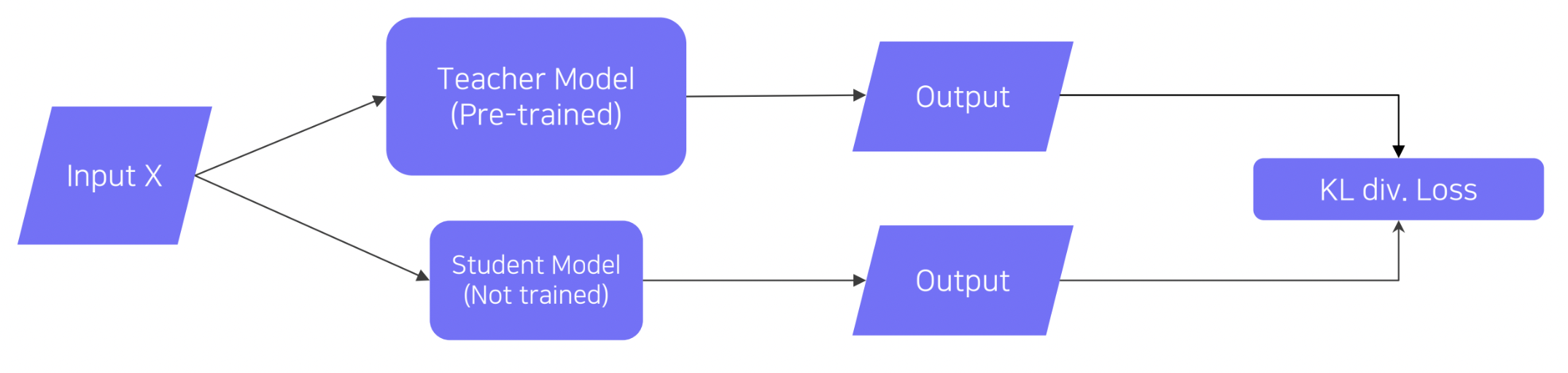
먼저 사전 학습시킨 Teacher model을 준비하고, Student model을 초기화합니다. 이후 같은 입력 X에 대한 Teacher model과 Student model 각 출력을 바탕으로 KL divergence loss를 계산하여 Student model을 학습시킵니다. 이떄 KL divergence loss를 활요할 경우 두 출력 간의 distribbution이 비슷하게 만들어지도록 학습이 진행하기 때문에, Student model이 Teacher model의 행동을 모방하도록 시키는 학습 방식이이라고 이해하면 됩니다.
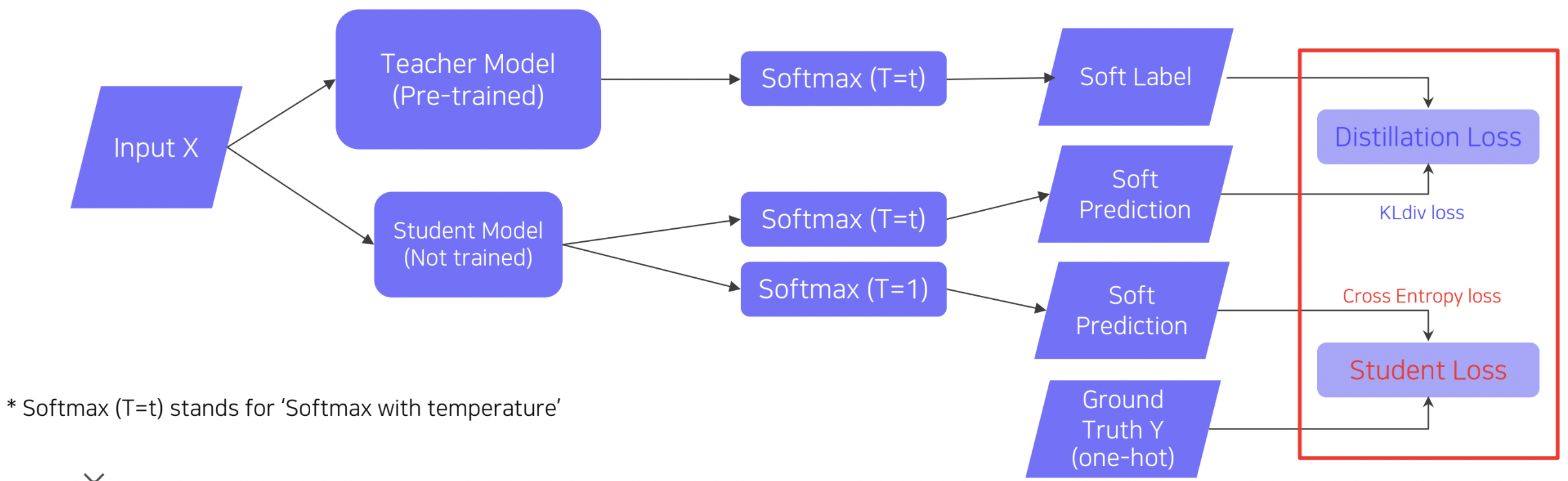 이 세팅에서는 두가지 Loss를 사용합니다. 하나는 앞서 설명했었던 KL div를 계한하는 Distilation Loss, 또 다른 하나는 Ground truth와 Student model의 출력을 바탕으로 cross-entropy loss를 계산하는 Student Loss 입니다.
이 세팅에서는 두가지 Loss를 사용합니다. 하나는 앞서 설명했었던 KL div를 계한하는 Distilation Loss, 또 다른 하나는 Ground truth와 Student model의 출력을 바탕으로 cross-entropy loss를 계산하는 Student Loss 입니다.
. Distillation Loss와 Student Loss의 가중합을 최종적인 Loss 값으로 사용
Distillation Loss의 경우 앞서 설명하였듯이 Teacher model의 행동을 모방
Student Loss의 경우 정답을 맞추기 위한 것
. 첫 번째로 Teacher model의 경우, softmax 출력 값에 argmax를 수행한 hard label(one-hot vector)이 아닌 softmax 출력 값을 그대로 활용하는 soft label의 형태로 결과를 출력하여, 이 출력 값을 Loss 계산에 사용한다는 것입니다.
 두 번째는 softmax 함수에 Temerature T값을 인자로 입력한다는 것입니다. 위의 수식에서 확인할 수 있는 것과 같이 temperature를 입력해주게 되면 보다 smooth한 결과값을 얻을 수 있어, 결과적으로 Student model이 Teacher model의 동작을 더욱 더 잘 모방할 수 있게됩니다.
두 번째는 softmax 함수에 Temerature T값을 인자로 입력한다는 것입니다. 위의 수식에서 확인할 수 있는 것과 같이 temperature를 입력해주게 되면 보다 smooth한 결과값을 얻을 수 있어, 결과적으로 Student model이 Teacher model의 동작을 더욱 더 잘 모방할 수 있게됩니다.
- Leveraging unlabeled datasetfor traing
Semi-supervised Learning
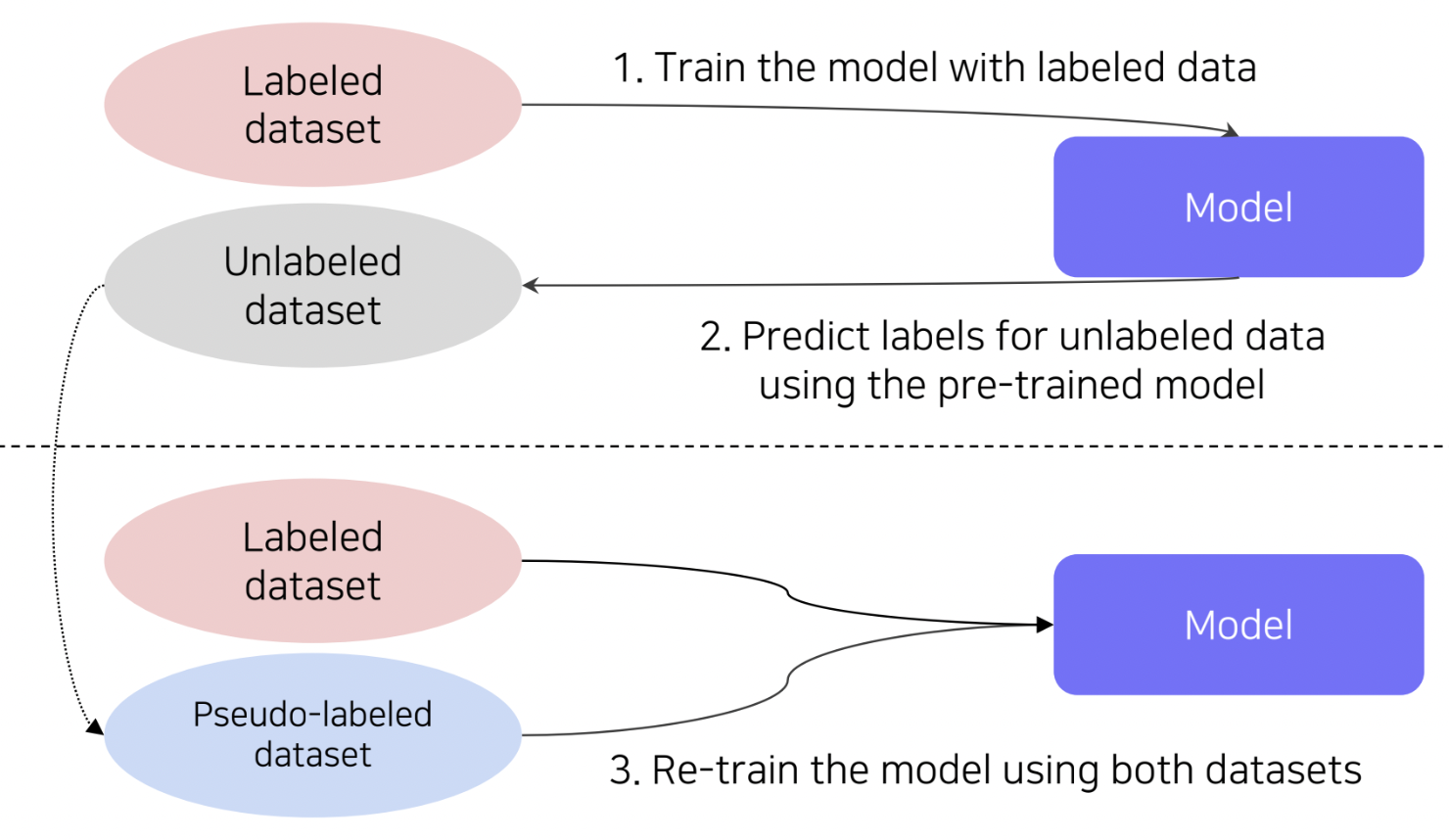 Semi-supervised Learning은 레이블링된 데이터를 활용하는 것과 더불어 레이블링되지 않은 데이터를 효과적으로 학습에 활용하는 학습 방법입니다. 즉 두 가지 데이터를 모두 학습에 활용하여 데이터 부족 문제를 효과적으로 완화하는 방법이라고 볼 수 있습니다. 구체적인 예시로 다음의 그림과 같이 pseudo-labeling을 활용하는 방법이 있습니다.
Semi-supervised Learning은 레이블링된 데이터를 활용하는 것과 더불어 레이블링되지 않은 데이터를 효과적으로 학습에 활용하는 학습 방법입니다. 즉 두 가지 데이터를 모두 학습에 활용하여 데이터 부족 문제를 효과적으로 완화하는 방법이라고 볼 수 있습니다. 구체적인 예시로 다음의 그림과 같이 pseudo-labeling을 활용하는 방법이 있습니다.
Self-training
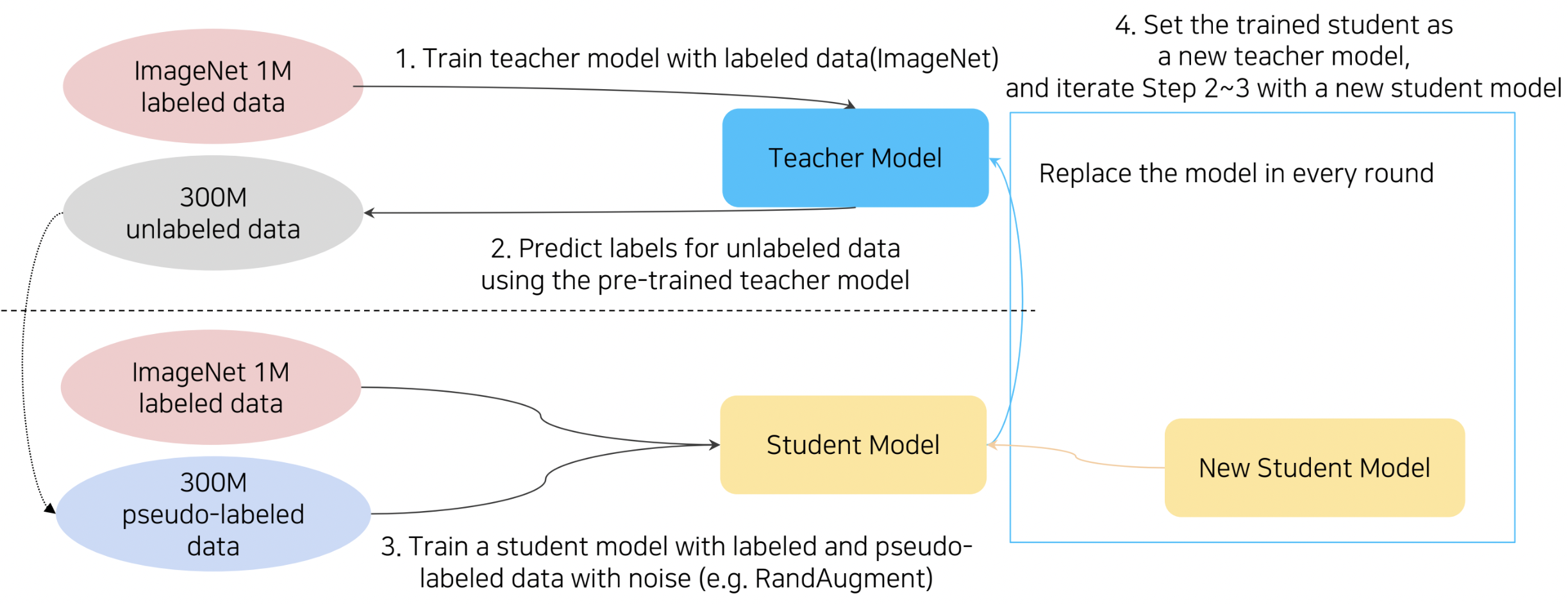 이 방법론은 위의 그림에서 확인할 수 있듯이 Self-training with nosiy student라고도 명명됩니다. 먼저 ImageNet(labeled dataset)으로 Teacher model을 학습시킨 후, 훨씬 큰 사이즈의 레이블링되지 않은 데이터에 대해 pseudo-labeling을 수행합니다. 이후 pseudo-labeled 데이터셋과 ImageNet을 합한 데이터에 RandAugment를 적용하여 Augmentation시킨 데이터셋을 활용하여 Student model을 학습합니다. 이때 주의할 점은 Knowledge Distillation에서는 일반적으로 Student model의 사이즈를 Teacher model의 사이즈보다 작게 설정해주었는데, Self-training에서는 반대로 Student model의 사이즈를 더 크게 설정해준다는 점입니다. 이후 이 Student model을 다시 Teacher model로 대체하여, pseudo-labeling을 수행하고 새로운 Student model을 학습시키는 과정을 2-4번 가량 반복합니다. 다음의 그림에서 각 반복에 따른 구체적인 수행 과정을 확인하실 수 있습니다.
이 방법론은 위의 그림에서 확인할 수 있듯이 Self-training with nosiy student라고도 명명됩니다. 먼저 ImageNet(labeled dataset)으로 Teacher model을 학습시킨 후, 훨씬 큰 사이즈의 레이블링되지 않은 데이터에 대해 pseudo-labeling을 수행합니다. 이후 pseudo-labeled 데이터셋과 ImageNet을 합한 데이터에 RandAugment를 적용하여 Augmentation시킨 데이터셋을 활용하여 Student model을 학습합니다. 이때 주의할 점은 Knowledge Distillation에서는 일반적으로 Student model의 사이즈를 Teacher model의 사이즈보다 작게 설정해주었는데, Self-training에서는 반대로 Student model의 사이즈를 더 크게 설정해준다는 점입니다. 이후 이 Student model을 다시 Teacher model로 대체하여, pseudo-labeling을 수행하고 새로운 Student model을 학습시키는 과정을 2-4번 가량 반복합니다. 다음의 그림에서 각 반복에 따른 구체적인 수행 과정을 확인하실 수 있습니다.
bias(편황됨)
Image Classification (2) : 대표 모델
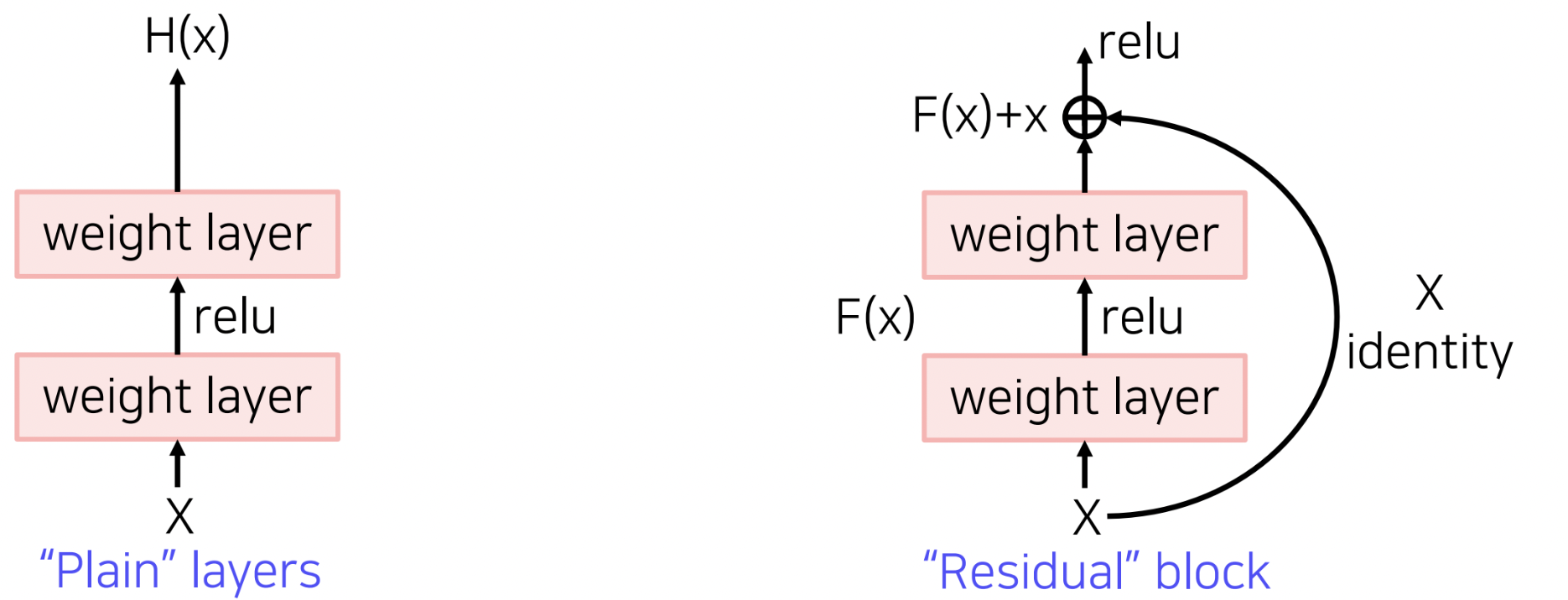
단순히 네트워크를 깊게 쌓게된다면 최적화하기 어렵다는 문제가 발생합니다. 대표적인 원인으로 Gradient Vanishing/Exploding 현상이 있는데, 이는 깊은 네트워크에서 역전파 알고리즘을 수행할 경우, Gradient 값이 너무 커지거나(Exploding), 소실에 가까울 정도로 너무 작아지는(Vanishing) 현상입니다. 추가적으로 계산복잡도가 증가하여 하드웨어 요구사항이 까다로워지는 등의 원인이 있습니다
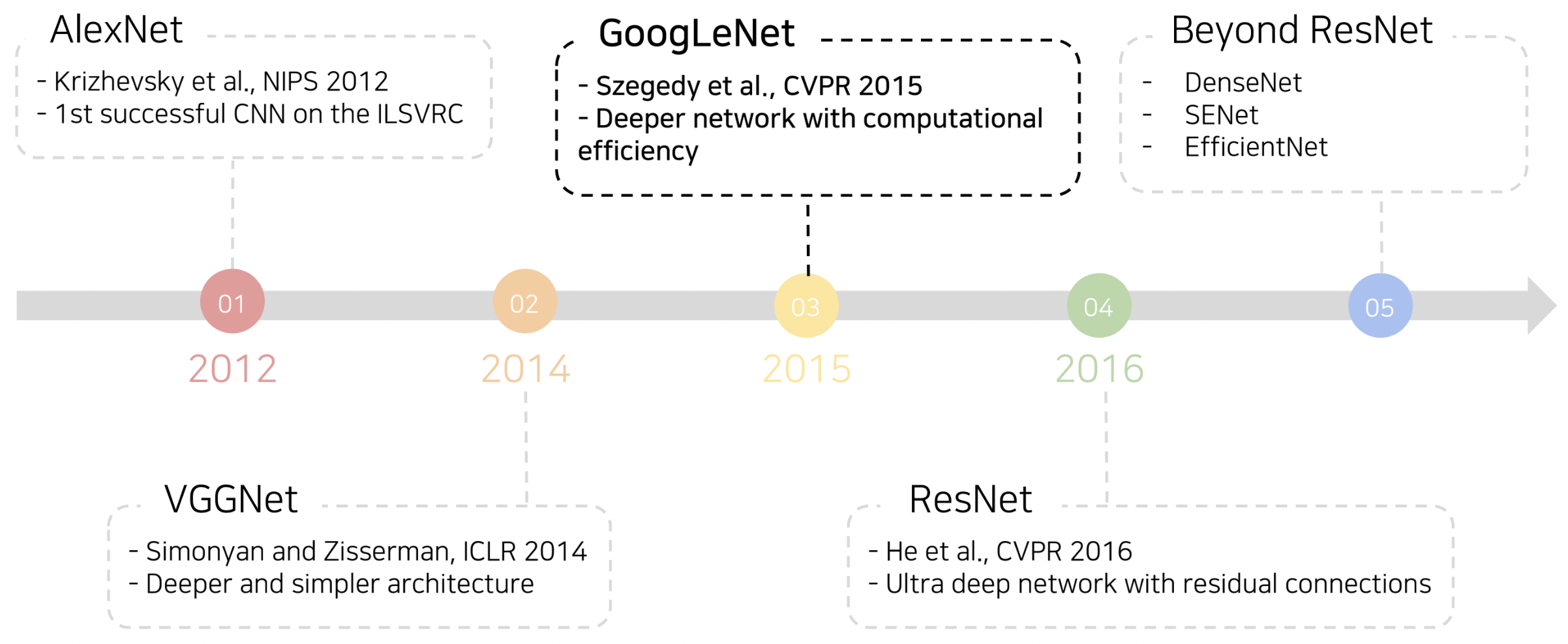
GoogLeNet
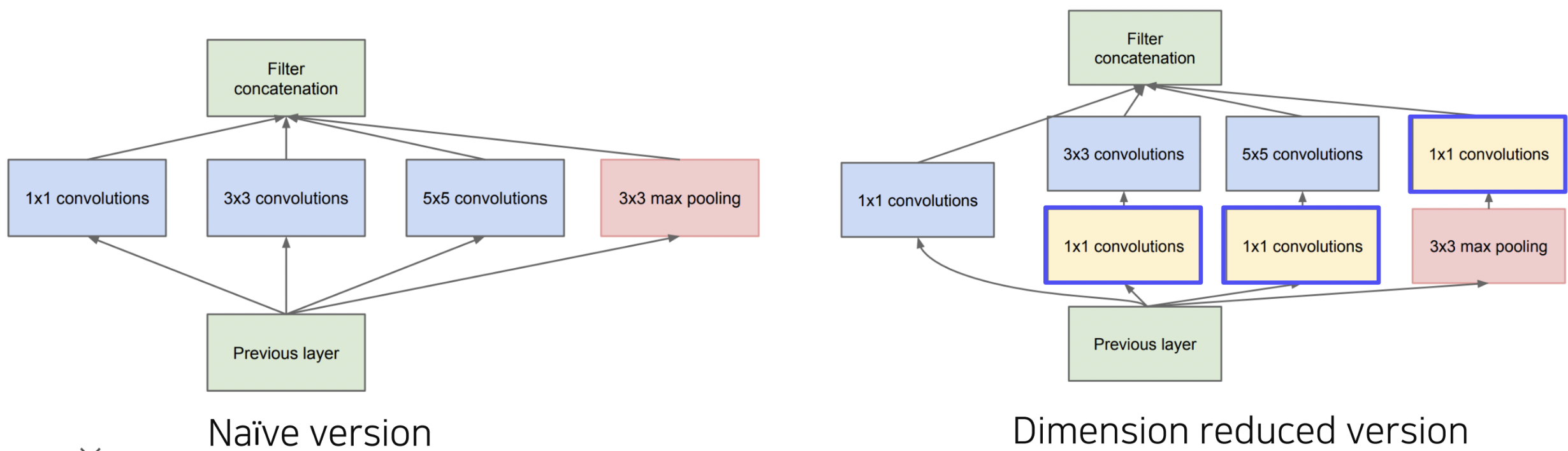
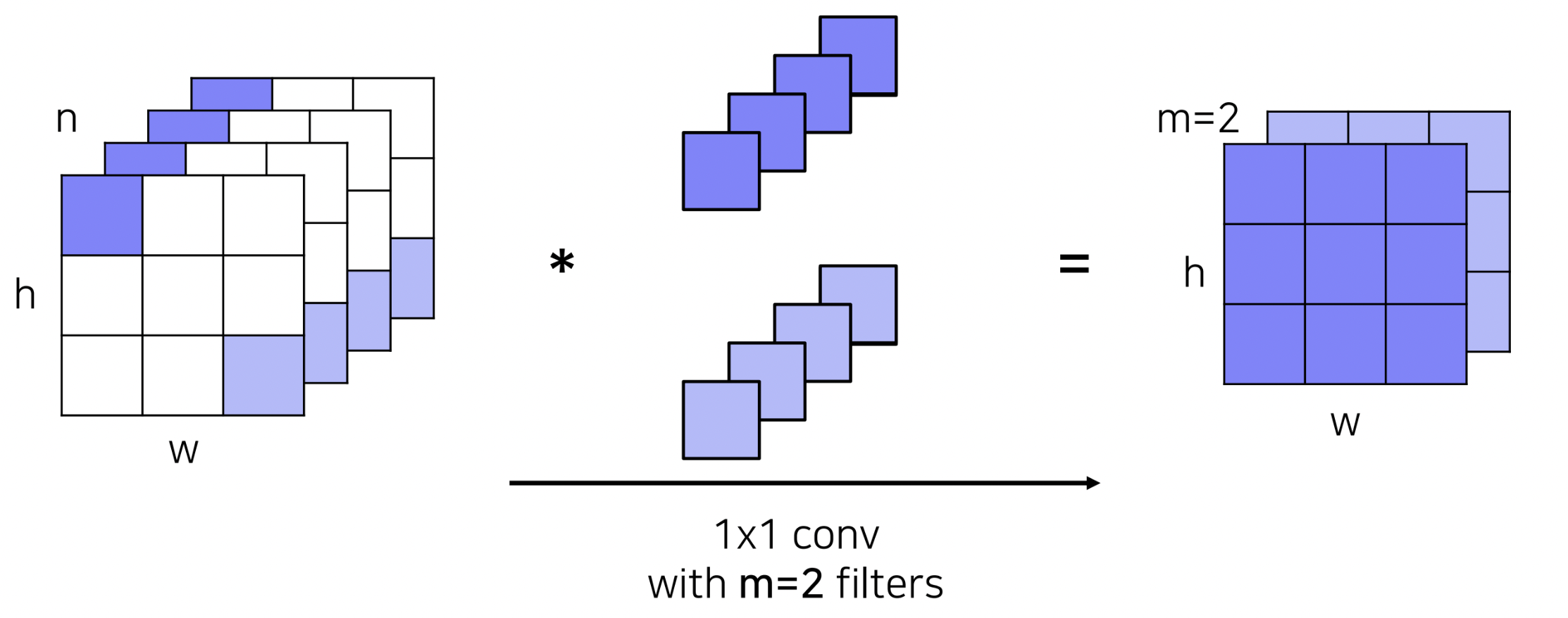
GoogLeNet에서는 Inception module이라는 새로운 구조를 제안했습니다. 이는 하나의 층에서 다양한 사이즈의 필터를 활용하고,이후 각 필터를 거친 출력 값을 channel 축으로 concat해줌으로써, 다양한 측면의 특징을 추출하겠다는 시도로 볼 수 있겠습니다.
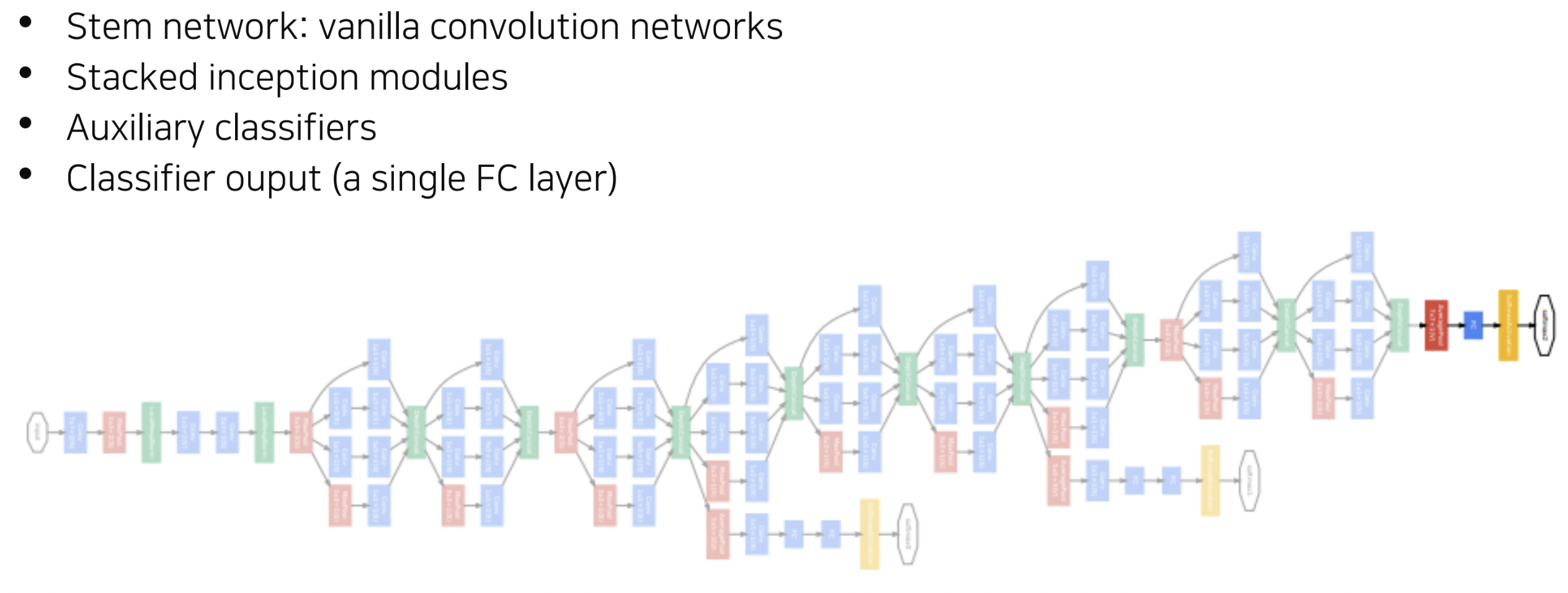 이제 GoogLeNet의 전체 구조를 살펴보겠습니다. 위의 그림에서 확인할 수 있듯이 Stem network는 vanilla convolution network로 구성됩니다. 이후 앞서 살펴보았던 Inception module을 중첩해서 쌓는 형태로 구성이 되는데, 네트워크의 중간중간에 auxiliary classifier가 추가적으로 구성되어있습니다. Auxiliary classifier의 경우, 강의 초반에 언급했던 gradient vanishing 문제를 완화하기 위해 추가되었으며, 레이어의 중간중간에 추가적인 gradient를 주입시키는 방식이라고 이해하시면 될 것 같습니다. 물론 이는 학습에만 사용되고, test time에서는 사용하지 않습니다.
이제 GoogLeNet의 전체 구조를 살펴보겠습니다. 위의 그림에서 확인할 수 있듯이 Stem network는 vanilla convolution network로 구성됩니다. 이후 앞서 살펴보았던 Inception module을 중첩해서 쌓는 형태로 구성이 되는데, 네트워크의 중간중간에 auxiliary classifier가 추가적으로 구성되어있습니다. Auxiliary classifier의 경우, 강의 초반에 언급했던 gradient vanishing 문제를 완화하기 위해 추가되었으며, 레이어의 중간중간에 추가적인 gradient를 주입시키는 방식이라고 이해하시면 될 것 같습니다. 물론 이는 학습에만 사용되고, test time에서는 사용하지 않습니다.
ResNet
ResNet은 100개 이상의 깊은 층을 갖는 구조를 가지고 ImageNet에서 최초로 인간보다 뛰어난 성능을 달성하며, 더 깊은 층을 쌓을수록 성능이 좋아진다는 것을 보여준 첫 논문입
 위의 그래프는 각각 20개, 56개의 레이어로 구성된 네트워크의 학습, 테스트 에러를 보여주고 있습니다. 연구자들은 네트워크의 층이 깊어지고, 파라미터 수가 증가할 수록 오버피팅에 취약하여 학습 에러는 비교적 낮아질 것이라고 생각했었습니다. 허나 그래프에서는 56개의 레이어로 구성된 네트워크의 학습 에러가 20개의 레이어로 구성된 네트워크보다 크게 측정되었고, 연구자들의 생각과 반대되는 결과를 보여주었습니다. 연구자들은 이러한 결과를 통해 층이 깊어질수록 오버피팅 문제가 아닌 degradation 문제로 인해 최적화하기 어려워져서 낮은 성능을 보이는 것이라고 결론내립니다.
위의 그래프는 각각 20개, 56개의 레이어로 구성된 네트워크의 학습, 테스트 에러를 보여주고 있습니다. 연구자들은 네트워크의 층이 깊어지고, 파라미터 수가 증가할 수록 오버피팅에 취약하여 학습 에러는 비교적 낮아질 것이라고 생각했었습니다. 허나 그래프에서는 56개의 레이어로 구성된 네트워크의 학습 에러가 20개의 레이어로 구성된 네트워크보다 크게 측정되었고, 연구자들의 생각과 반대되는 결과를 보여주었습니다. 연구자들은 이러한 결과를 통해 층이 깊어질수록 오버피팅 문제가 아닌 degradation 문제로 인해 최적화하기 어려워져서 낮은 성능을 보이는 것이라고 결론내립니다.
출처
- 메인 학습 https://www.boostcourse.org/ai340/lecture/1463030
댓글남기기